
4가지 CNN 살펴보기: AlexNET, VGG, GoogLeNet, ResNet
레이어의 수가 많아지면 성능이 좋아질 여지가 많아진다.
일반적으로 레이어를 100개, 1000개 쌓는다고 성능이 좋아지지는 않는다.
레이어를 딥하게 쌓으면서 성능을 좋아지게 만드는 방법은?
1. AlexNet

- 파라미터의 수가 몇개인지를 먼저 알아야 한다
- 11x11 convolution, channel이 3
- 11, 11, 3, 48 ...
- 두 개로 나눠져 있는 이유, GPU가 좋지 않아서.
ReLU(Rectified Linear Unit)
- 웬만하면 ReLU를 쓰는 게 성능이 좋다는 게 현재 중론
LRN(Local Response Normalization)
- 어떤 convolution feature map에 일정 부분만 값을 높게 갖고, 나머지는 값을 낮게 해주고 싶은 것.
(모든 값을 같게 해주는 게 아니라)
[ Regularization ]
1) data augmentation: 데이터를 늘린다
- label preserving transformation이 중요하다
- 분류하고 싶은게 물체가 아니라 숫자라면 Flip augmentation을 하면 안 된다
- 내가 찾고 싶은 물체가 어떤 것인지, 도메인을 분명하게 알고 찾아야 한다
- Smaller Patch(224 x 224)
- Color variation
- rgb 이미지이기 때문에 각각의 값에 특정 값을 더한다
2) Dropout: 학습 시에 해당 노드를 0으로 만들어 주는 것, 알렉스넷에서는 output에 0.5만큼 곱하는 방법 사용
Conv2D
- 파라미터의 수를 잘 계산할 줄 알아야 한다
2. VGG
- 합성곱 계층과 풀링 계층으로 구성되는 '기본적'인 CNN
- VGG 16, 19를 많이 활용(레이어가 16, 19)
- 3x3의 작은 필터를 사용한 합성곱 계층을 연속으로 거친다
- 합성곱 계층을 2~4회 연속으로 풀링 계층을 두어 크기를 절반으로 줄이는 처리를 반복
- 마지막에는 완전연결 계층을 통과시켜 결과를 출력
3. GoogLeNet
- Google + LeNet
- 22layers
- 인셉션 모듈(가로 방향에 '폭'이 있다)을 잘 활용
[ Inception module ]
- Naive inception module
- Actual inception module
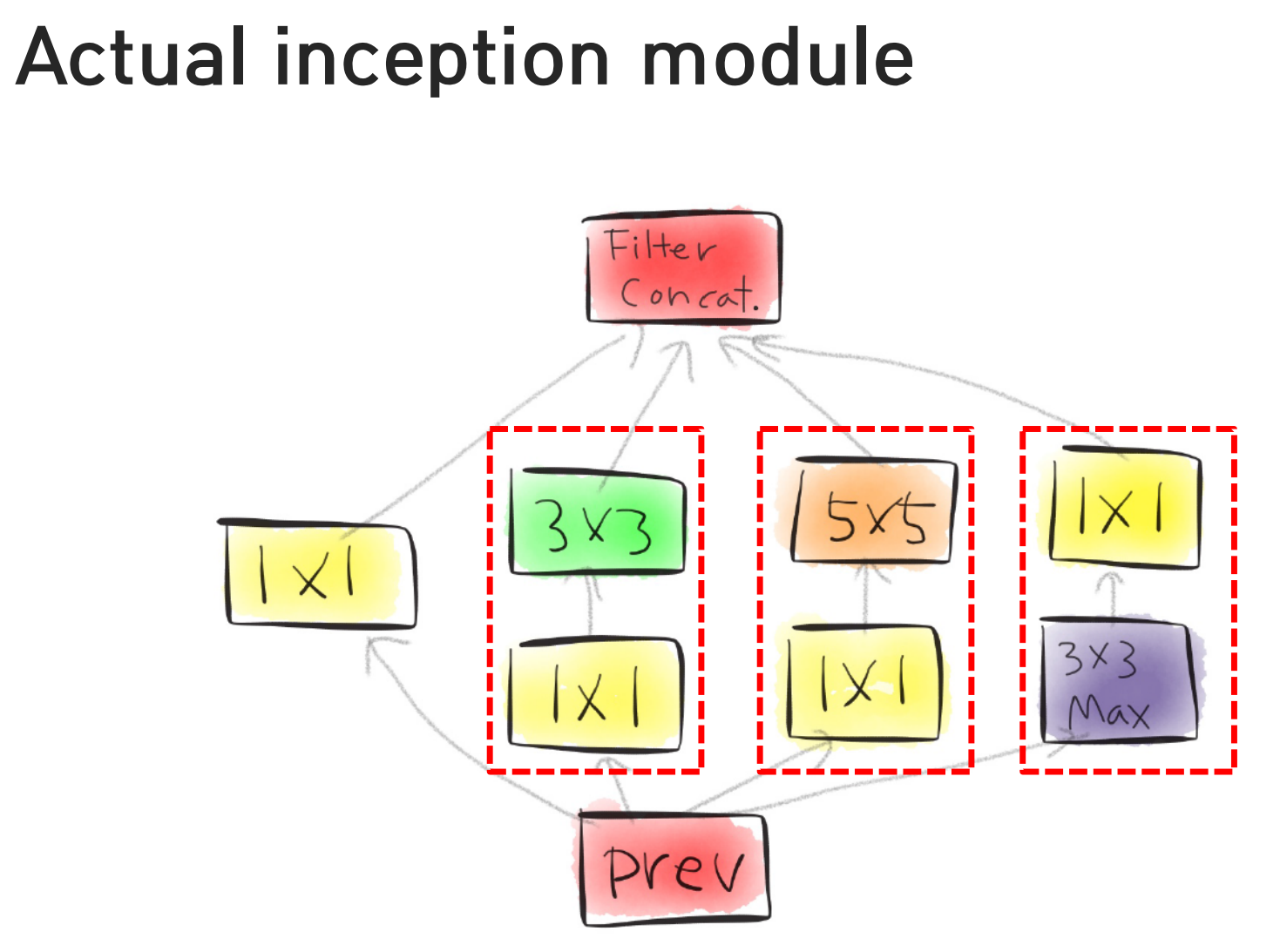
- 차이점: 1x1 convolution 추가 된 것이 전부
[ one by one convolution ]
- 채널의 수를 중간에 한 번 줄였을 때, 이 네트워크를 정의하는 파라미터의 수가 줄어든다
- 레이어가 오히려 하나 더 쓰였는데 파라미터의 수가 줄어든다
- 어떻게 가능할까? convolution레이어의 파라미터를 정의하는 건 input 채널과 output채널
googLeNet
- 계속 그게 반복되는 구조
- 채널을 줄였기 때문에 굉장히 좋은 아이디어
인셉션 모듈이 가지는 장점이 한 가지 더 있다
- 여러 개의 갈림길로 인해 생기는 장점
- 어떤 neural net이 있을때, receptive field
- 항상 동일한 크기의 이미지를 보고 숫자를 취합해서 얻어진 숫자
- 내가 찾고 싶은 물체의 크기가 어떤건 되게 크고 작을 수 있다
- 그런데 receptive field 크기가 고정 되어 있으면, 고정된 receptive field 크기 때문에 제대로 연산이 되지 않을 수 있다
- 입력 이미지에 취합된 정보가 미치는 repective field가 다양해질 수 있다
- 훨씬 더 deep한 네트워크를 쌓았는데도 불구하고 성능을 많이 올릴 수 있다
- VGG 네트워크: 19단, 구글넷: 22단
- 여기에 사용된 파라미터의 수는 구글넷이 VGG보다 절반 이상 훨씬 더 파라미터가 적다
- 네트워크는 훨씬 더 딥해졌는데 그 네트워크를 정의하는 파라미터의 수는 훨씬 더 적어졌다 >> dimension reduction
- 동일한 테크닉이 Resnet에도 들어가 있다
Inception v4
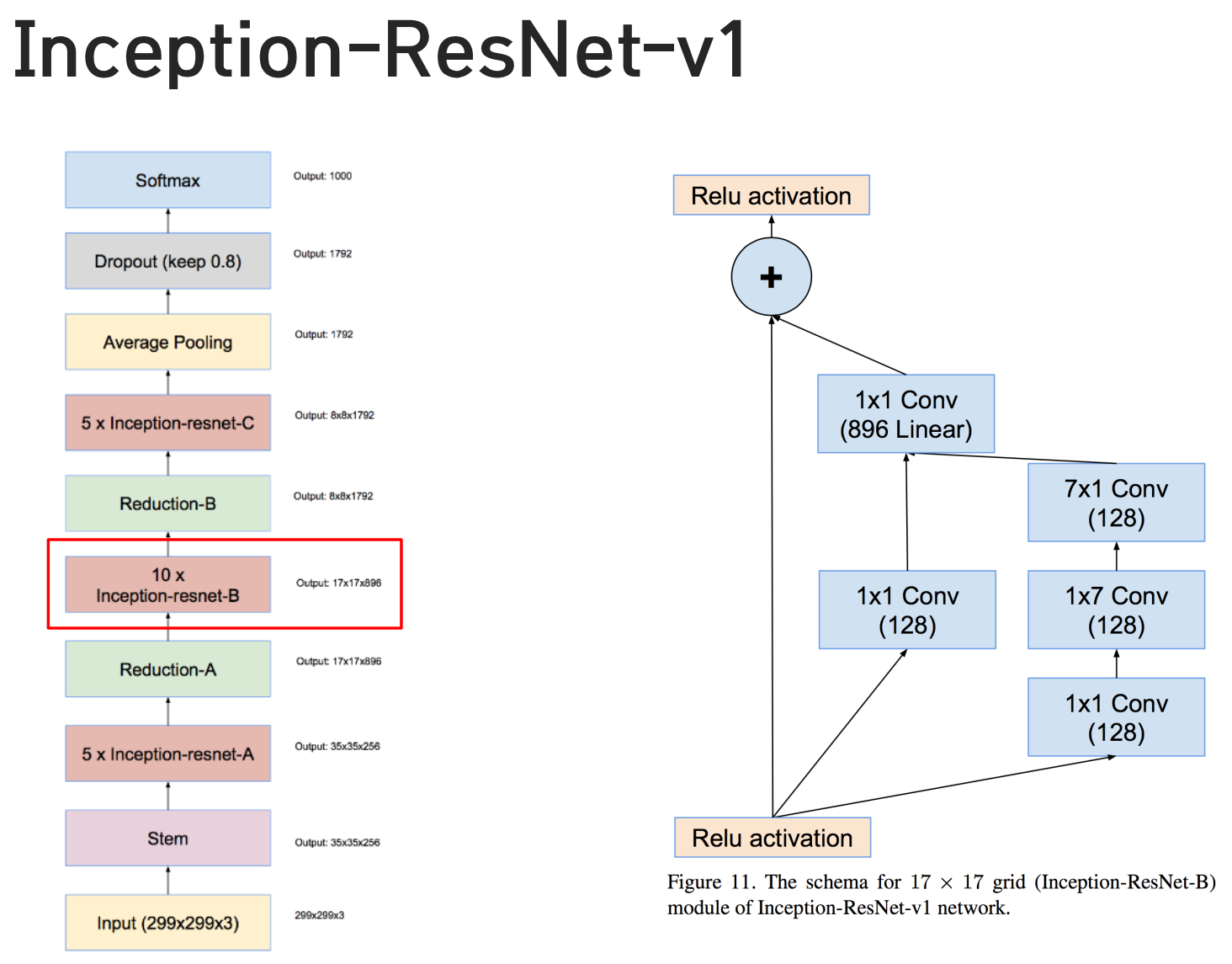
- 비교적 최근에 발표된 모델
- 파라미터를 줄이기 위해서 어디까지 노력했냐? 확인가능
- inception v4에서는 5x5가 더 이상 등장하지 않는다
- 7x1, 1x7, 번갈아가면서 쓴다
4. ResNet(Residual Network)
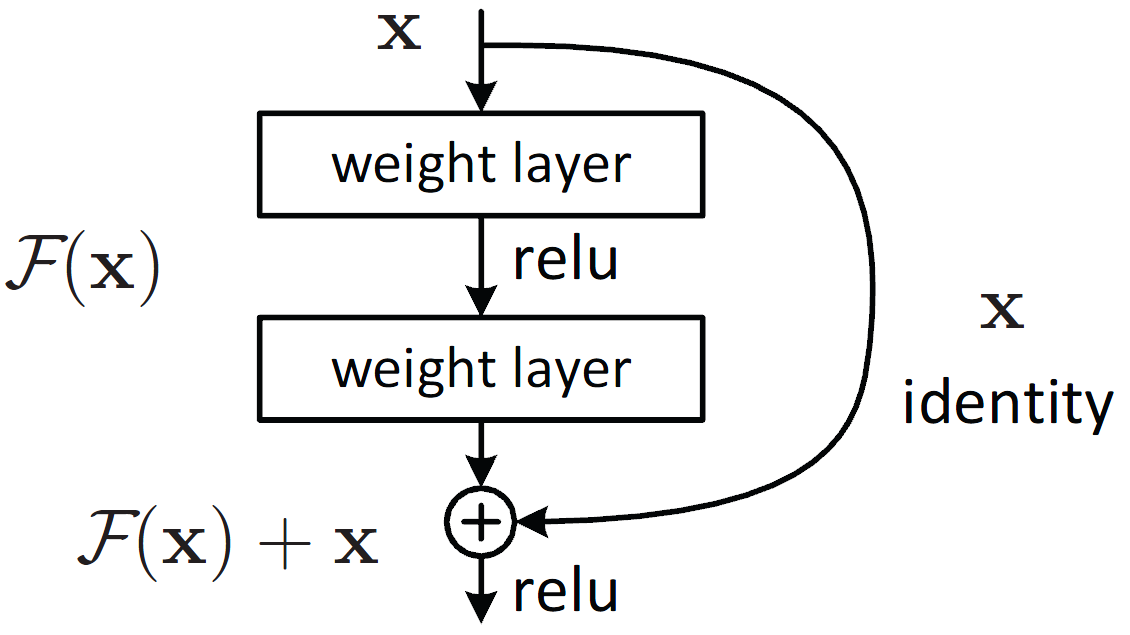
- residual connection 사용
- 152 layers
- 동일한 네트워크가 여러 가지에 1등을 했다 >> 범용적으로 사용할 수 있다
- 네트워크가 딥한 게 항상 좋냐? >> 딥하다고 잘 되지 않는다: degradation
- vanishing gradients 문제
- 이를 해결하기 위해 스킵 연결(skep connection) 도입
- 층의 깊이에 비례해 성능을 향상시킬 수 있게 한 핵심
- 입력 데이터를 '그대로 흘린다' : 기울기의 소실 줄여준다
- 역전파 때 스킵 연결이 신호 감쇠를 막아준다
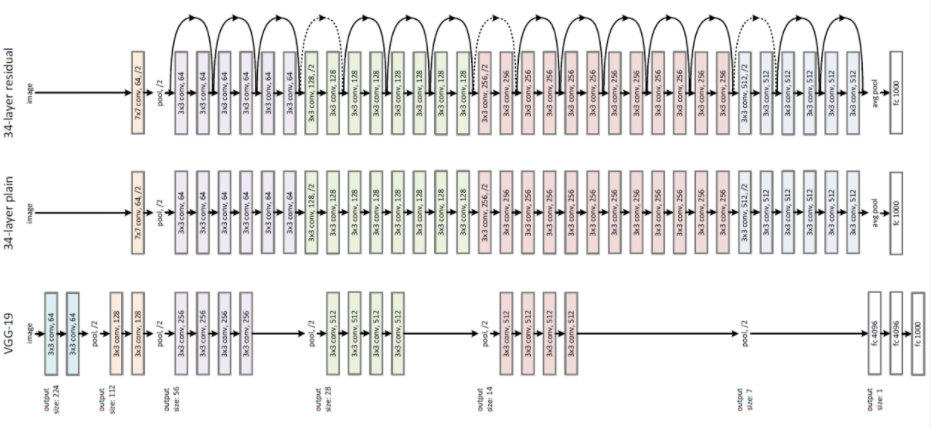
- 합성곱 계층을 2개 층마다 건너뛰면서(skip connection) 층을 깊게 한다 >> 152 layers
[ Residual Learning building block ]
- 입력을 출력에 더한다: 입력과 출력의 dimension이 같아야 한다
- 중간에 있는 레이어는 입력과 아웃풋 사이의 차이(residual)만을 학습
- y = y + shortcut
- residual: 쉽고 잘 된다
Deeper bottle architecture
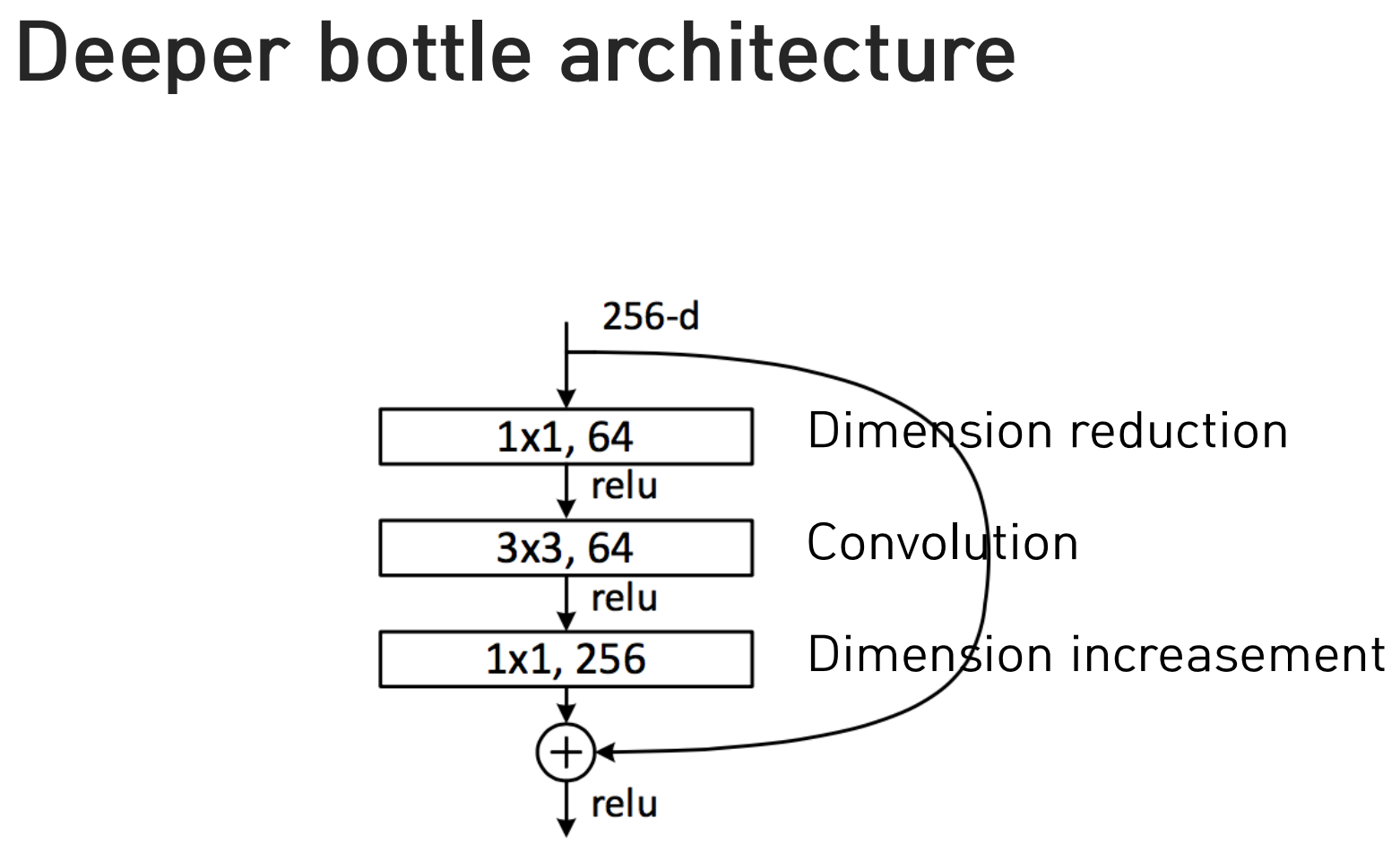
- 파라미터를 줄인다
- 1x1 convolution 사용
- 왜 마지막에 1x1? 처음에는 채널을 줄인다, 마지막에는 더해줘야 하니까 다시 256채널로 복원이 되어야 한다
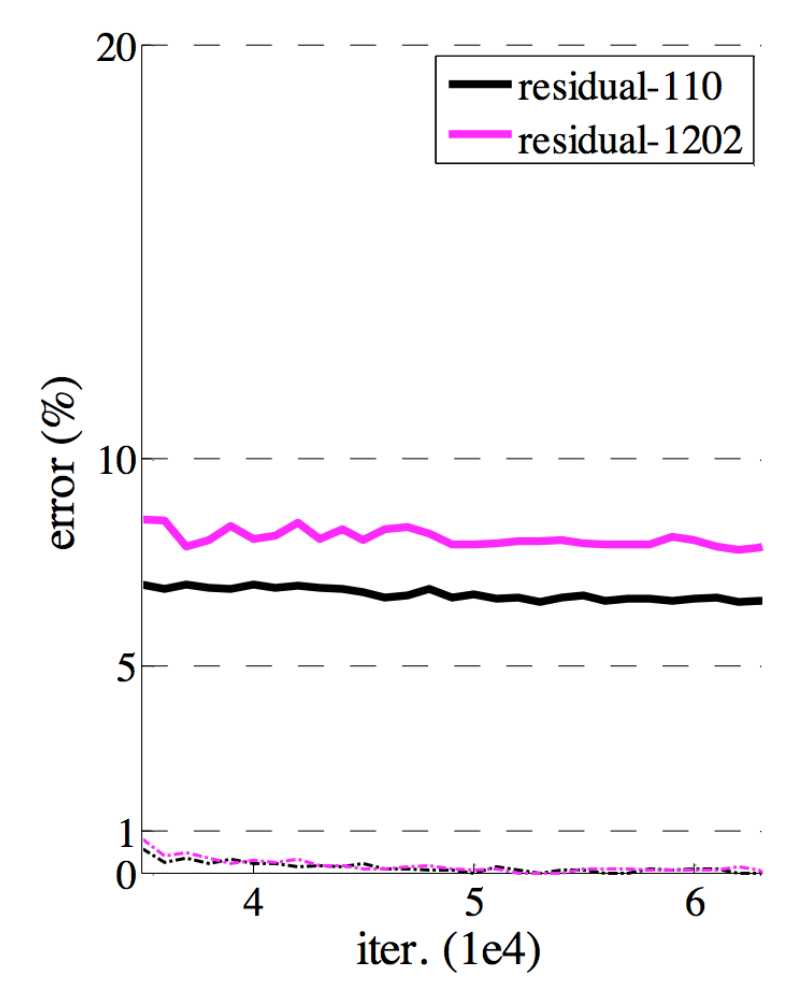
- 100단 짜리랑 1202레이어, 성능의 차이가 없다
- 20단보다는 100단짜리가 훨씬 성능이 좋아졌는데, 1000개가 넘어가면 성능의 차이가 없어졌다
출처1: edwith <논문으로 짚어보는 딥러닝의 맥> by 최성준
https://www.edwith.org/deeplearningchoi/lecture/15296?isDesc=false
[LECTURE] 4가지 CNN 살펴보기: AlexNET, VGG, GoogLeNet, ResNet : edwith
학습목표 최신 CNN 구조 중 AlexNet, VGG, GoogLeNet, ResNet 이렇게 4가지 구조에 대해서 알아보겠습니다. 위 4가지 구조들은 일반적으로 딥러닝의 유명한 ... - 커넥트재단
www.edwith.org
출처2: 밑바닥부터 시작하는 딥러닝) 8장 딥러닝