구텐베르크의 금속활자가 기술적 혁신을 넘어 역사적 도구가 된 것도 '지식의 개인화'에 기여했기 때문이라는데, 데이터 역시 그에 필적할 만한 도구로 기능할지 기대된다.
데이터를 그런 도구로 만들려면 데이터 활용에 필요한 생각 근육을 키워야 한다. ... 데이터는 어디가지나 생각을 거드는 도구이지, 그 자체가 생각이 될 수는 없기 때문이다.
데이터는 분석의 대상이 아닌 소통의 도구이고 그렇기에 언어를 배우듯 접근해야 한다.
(서문 中)
- 글로벌 주요 기업들이 가진 데이터의 약 60-73%는 전혀 분석되지 못하고 사장된다(2019, 포레스터Forrester)
- 처리되지 않고 막연히 '언젠간 쓸 일이 있겠지' 하며 쌓아둔 데이터: 다크 데이터(dark data)
- 전 세계 데이터의 80% 이상(가트너Gartner) / 약 88%(IBM research) -> 다크 데이터
- "비즈니스 가치가 있다고 여기는 데이터는 15%에 불과하다"
"저장과 관리에 드는 비용이 2020년에는 약 3조 3,000억 달러에 육박할 수 있을 것"(베리타스Veritas)
- 데이터를 사용하지 않는 데서 발생하는 기회비용(캐터필러Caterpillar의 예)
실시간으로 전송되는 고객 데이터를 거들떠보지 않은 딜러들.
(p.15-16)
디지털 대전환(Digital Transformation) 전략의 끝은 데이터를 쌓는 게 아니라, 쓰게 하는 데 있다는 것이다.
데이터를 효과적으로 사용하지 못하는 데 따르는 비용 규모는 일반 기업의 경우 전체 매출의 8~12%, 서비스업 회사의 경우 총비용의 40~60%에 육박할 것이라는 연구 결과도 있다.
(p.17)
데이터를 쌓아두기만 할 경우 발생하는 문제 >
- 검증 비용의 문제.
- 보안과 컴플라이언스(compliance) 문제.
(p. 17-18)
A 은행의 예)- 모든 운영 영역에서 데이터를 통한 혁신을 만들어내고자 함
- 이를 위해: 최대한 많은 데이터를 모아 데이터 레이크(data lake, 가공되지 않았지만 언제든 접근 가능하도록 만든 기업 내 데이터 시스템 또는 리파지토리(repository)를 만들고자 함 -> 실패: 데이터 스웜프(data swamp)
- 왜? '전체 비즈니스 맥락에 맞는 데이터 수집 목적의 설계'를 무시함
(p. 21-22)
이제 우리가 해야 할 일 >
1. 데이터 검증 속도를 가속화하기
2. 목적이 데이터의 생성, 활용, 폐기 등 전체 생애 주기를 주도할 수 있도록 데이터 감각을 날카롭게 다듬어놓기
(p.23 - 24)
글로벌 BDA(Big Data & Business Analytics solution) 시장 규모
- 2019년 약 1,891억 달러, 2018-2022년 사이 연평균 약 13.2%의 고속성장세 (IDC 발표)
(p.24)
데이터 사일로 현상
데이터 리터러시의 정의
"데이터 리터러시는 데이터를 건전한 목적과 윤리적인 방법으로 사용한다는 전제하에, 현실 세상의 문제에 대한 끊임없는 탐구를 통해 질문하고 답하는 능력을 말한다. 이를 위해 핵심적으로 필요한 것은 실천적이고도 창의적인 능력들인데 전문가들의 데이터 취급 역량도 일부 포함된다. 예를 들면 데이터를 취사선택하고, 가다듬고, 분석하고, 시각화하고, 비판하고, 해석하는 역량, 더 나아가 스토리를 전개하며 소통하고 일하는 방식을 개선하는 역량 등이 그 예다." (2016, 아니카 월프 Annika Wolff)
+ "사이언티스트들이나 전문가들이 아닌, 반드시 비전문가들에게 적용되어야 하는 개념이다. 전문가들은 리터러시라는 것 이상의 개념을 필요로 하기 때문이다." ~ 데이터 리터러시의 대중화를 기대
(p. 37-38)
데이터 = '언어' (가트너)
1) 역할- '어떤 질문에 답하기 위해 데이터를 쓰는 것입니까?'- 데이터에 숨어있는 놀라운 의미와 통찰을 발견하는가의 여부는 우리의 감각에 달려있다.
2) 습득하는 방식
+) 맥락에 맞게(in context) 데이터를 읽어내는 것
- 맥락을 제대로 알아야 그에 맞춰 문제를 정확히 규정할 수 있고,
- 문제가 정확해야 적중도 높은 가설을 설정할 수 있으며,
- 가설이 명확해야 효율적인 검증 어프로치를 설계하는 것이 가능
- 어떤 데이터가 우리에게 필요한지 아닌지는 이러한 어프로치가 명확할 때에야 비로소 결정
(p. 37-38)
질리도록 많은 데이터의 양, 시각적으로 화려하게 채색된 데이터에 쉽게 속지 않으려면 사실성과 연관성, 충분성을 균형 있게 만족시키는지 파악하는 훈련을 해나가야 한다. (p.259)
데이터 획득 역량을 구성하는 기본은 "제가 필요로 하는 데이터는 이런 것입니다"라고 자신 있게 지목할 줄 아는.
자신이 원하는 것을 정확한 개념으로 표현할 줄 아는 사람은 데이터 분석을 위한 목적의식, 그리고 그 목적의식하에서 필요한 가설과 데이터 유형까지 정할 수 있는 사람이다. (p.261)
맥락을 안다는 것의 힘: 생존 편향의 오류
제2차 세계대전 당시 미군은 해군 전투기 생존율을 높이기 위해 한 가지 조사에 나섰다.
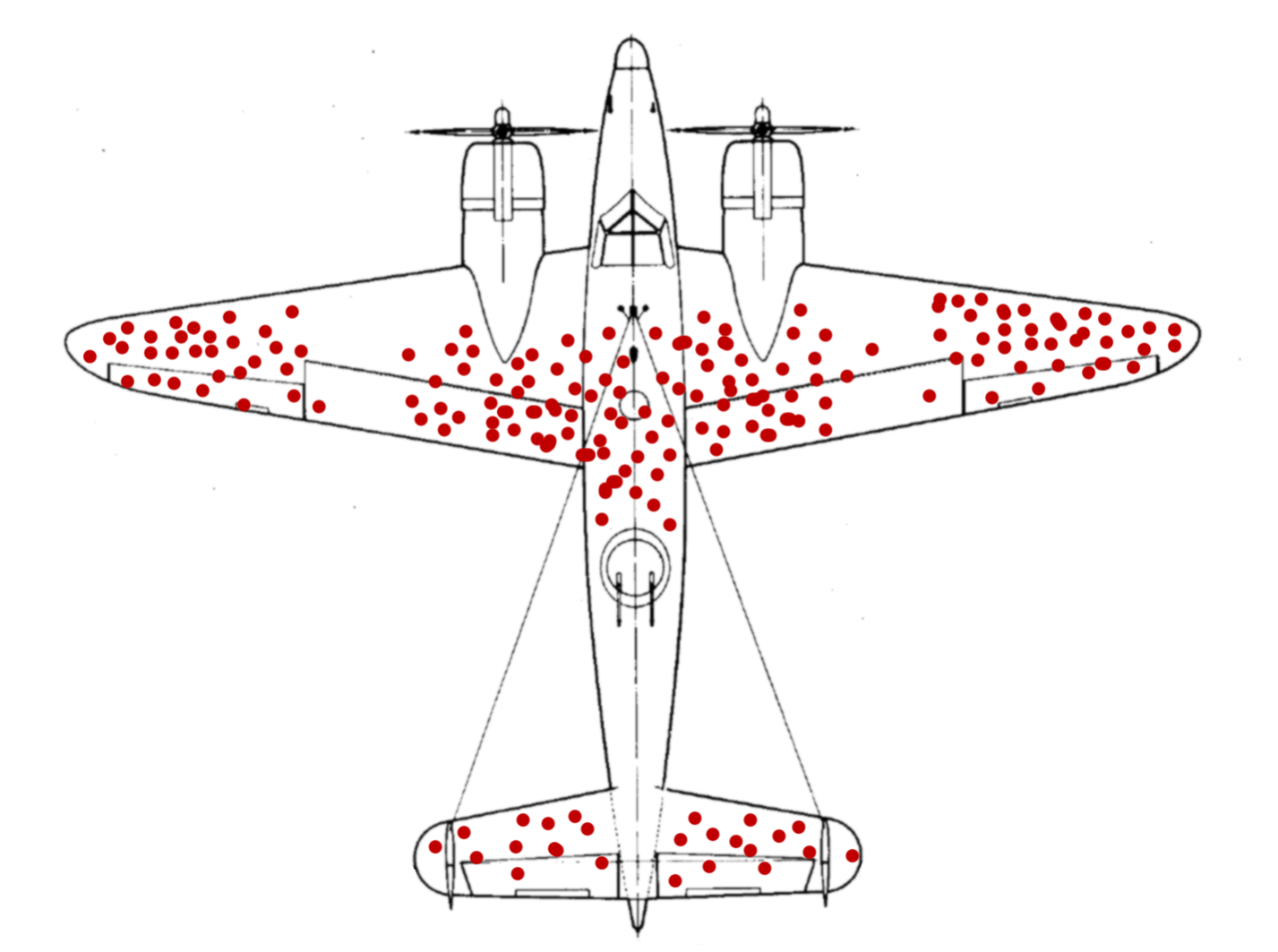
전투를 마친 비행기들을 대상으로 비행기가 어느 부분에 총알을 많이 받았는지를 조사한 미군은
각 비행기에 남아 있던 피탄 흔적을 다음과 같은 그림에 빨간색 점으로 표현했다.
부분별 피탄 개수의 데이터를 기반으로 당시 군 지휘부는 전투기의 생존율을 높일 수 있는 방안을 내달라고 통계연구그룹(SRG: Statistical Research Group)에 요청
그 결론에 따라 비행기에 철판을 덧대는 작업을 할 계획
-> '빨간 점이 많은 부분을 우선적으로 보강해야 한다'
=> "여러분, 피탄 흔적이 없는 곳을 보강해야 합니다. 전투에서 돌아오지 못한 비행기들은 바로 그 부분에 총알들을 맞았을 것이기 때문입니다." (에이브러햄 발드 Abraham Wald)
(p. 286~289)
'AI 교양' 카테고리의 다른 글
| <한 권으로 끝내는 AI 비즈니스 모델> 1장 리뷰 (0) | 2022.11.21 |
|---|---|
| 한 권으로 끝내는 비즈니스 모델 (0) | 2022.11.21 |